

int c;
for (long int a=999999999; a >0; a--)c=a*a*a*a*a*a*a*a*a*a*a*a*a*a;
cout << c;
这段代码用时5秒,编译器nvcc
还有很大进步空间
今年图灵奖得主是因为发明了RISC(Reduced Instruction Set Computer)获奖。其中Patterson在获奖后的演讲上说到这是一个New Computer Architecture Golden Age. 其中最有前途的是DSA (Domain Specific Architecture). 而把high level language和新的architecture结合对编译器的设计也是一个新的挑战。
不提DSA,在现有的cpu上优化代码也有千万倍的进步空间,主要在parallelism和memory optimization上。在18核intel上做同样的矩阵乘法,由interpreted language(Python)换到compiled language (C)可以有50倍的提升,这个基础上加入parallel loops可以有额外的7倍速度提升,在这个基础上进行memory optimization可以有额外20倍的速度提升,在这个基础上用到cpu相关的SIMD instructions可以有额外的9倍速度提升。
在理论上compiler或许可以对以上步骤进行优化,而事实上目前这其中的每一步都需要人来实现。python改写成c需要人来操作;parallel loops这一块有比较好的库,如openmp,但是还有很大空间;memory optimization老生常谈,任重道远;SIMD目前也是“usually require human labor”,因为还没有compiler可以使用SIMD instructions,在这一块研究搞出一些名堂,你就是下一个图灵奖得主( 据评论区@Menooker指出,一些现有的compiler已经可以实现auto vectorization。的确,并且这也是一个active research direction。只是目前auto vectorization还非常naive,只能optimize非常简单的loop而不能在loop里有太多control flow,而且程序员往往放心不下还要看看结果,这通常defeat the purpose,结果是许多人还是在用intrinsics手撸。不过我还是乐观的,无数大神们正在为之努力)
在Patterson的turing lecture中,有一页专门讲到后续的Research Opportunities。尽管他更看好Domain-specific architectures,但是也提到了General purpose application的优化也有很大的进步空间,也就是怎样设计compiler可以让代码在risc architecture上有成百上千倍的速度提升。
评论区 @月明星稀 :能不能贴个代码
上面提到的优化速度的数据源自CharlesE.Leiserson,NeilC.Thompson,JoelS.Emer,BradleyC.Kuszmaul,ButlerW.Lamp- son, Daniel Sanchez, and Tao B. Schardl, “There’s plenty of room at the top: What will drive growth in computer performance after Moore’s Law ends?” unpublished manuscript submitted for publication.
因为这篇论文还没有发表,所以我暂时拿不到代码,但是我已经给N. C. Thompson发邮件了,看看能不能要到。
我们在等的时候可以看看已有的代码。
https://akkadia.org/drepper/cpumemory.pdf 这篇关于内存优化的文章写得很好。大家可以读一读6.2.1,举的就是matrix multiplication的例子。这里就主要是我上面提到的“Memory Optimization”这一环,有一些Cache相关的优化,同时也加了一些SSE的SIMD优化(写的时候应该还没有AVX)。代码在Appendix A. 1,我在这里也贴一下吧。
#include <stdlib.h>
#include <stdio.h>
#include <emmintrin.h>
#define N 1000
double res[N][N] __attribute__ ((aligned (64)));
double mul1[N][N] __attribute__ ((aligned (64)));
double mul2[N][N] __attribute__ ((aligned (64)));
#define SM (CLS / sizeof (double))
int
main (void)
{
// ... Initialize mul1 and mul2
int i, i2, j, j2, k, k2;
double *restrict rres;
double *restrict rmul1;
double *restrict rmul2;
for (i = 0; i < N; i += SM)
for (j = 0; j < N; j += SM)
for (k = 0; k < N; k += SM)
for (i2 = 0, rres = &res[i][j], rmul1 = &mul1[i][k]; i2 < SM;
++i2, rres += N, rmul1 += N)
{
_mm_prefetch (&rmul1[8], _MM_HINT_NTA);
for (k2 = 0, rmul2 = &mul2[k][j]; k2 < SM; ++k2, rmul2 += N)
{
__m128d m1d = _mm_load_sd (&rmul1[k2]);
m1d = _mm_unpacklo_pd (m1d, m1d);
for (j2 = 0; j2 < SM; j2 += 2)
{
__m128d m2 = _mm_load_pd (&rmul2[j2]);
__m128d r2 = _mm_load_pd (&rres[j2]);
_mm_store_pd (&rres[j2],
} }
}
// ... use res matrix
return 0; }这里大家可以明显的看到一些loop unrolling和SIMD的技巧
simd优化,编译器做的不好,以至于科学计算库几乎都是手写simd指令。
从理论上来说,同样的逻辑,不同的编程语言写代码,运行速度不该有差别。而现在明显c/c++快,这就是问题了
软流水加自动向量化还是有搞头的 然而实现的好的软流水真心不多
clang-6能把
int s=0;
for(int i=0; i < n; i++)
s+=i;
优化成s=n*(n-1)/2
类似的循环求和公式clang支持的还有很多
如果你调过cpu上的计算kernel,手写过计算kernel的汇编,你会发现clang汇编的代码比高手手写的都不差,而且寄存器的使用,指令的排列,非常工整漂亮
最近搞CUDA搞得比较多,来说一下nvcc能够做的优化。这里主要是说明一下使用#pragma unroll的细节。先来看一下CUDA C代码段:
//#define FETCH_FLOAT4(pointer) (reinterpret_cast<float4*>(&(pointer))[0])
const int B_TILE_ROW_STRIDE=8;
__shared__ float Bs[2][BLOCK_SIZE_K][BLOCK_SIZE_N];
// load B from global memory to shared memory
#pragma unroll
for ( int i=0 ; i < BLOCK_SIZE_K; i +=B_TILE_ROW_STRIDE){
FETCH_FLOAT4(Bs[0][i][0])=FETCH_FLOAT4(B[i*N]);
}
__syncthreads();
FETCH_FLOAT4(C[threadIdx.x*N+threadIdx.y])=FETCH_FLOAT4(Bs[threadIdx.x][threadIdx.y]);上面代码没啥具体功能,就是测试一下#pragma unroll的结果,看看循环展开的效果。
汇编代码如下:
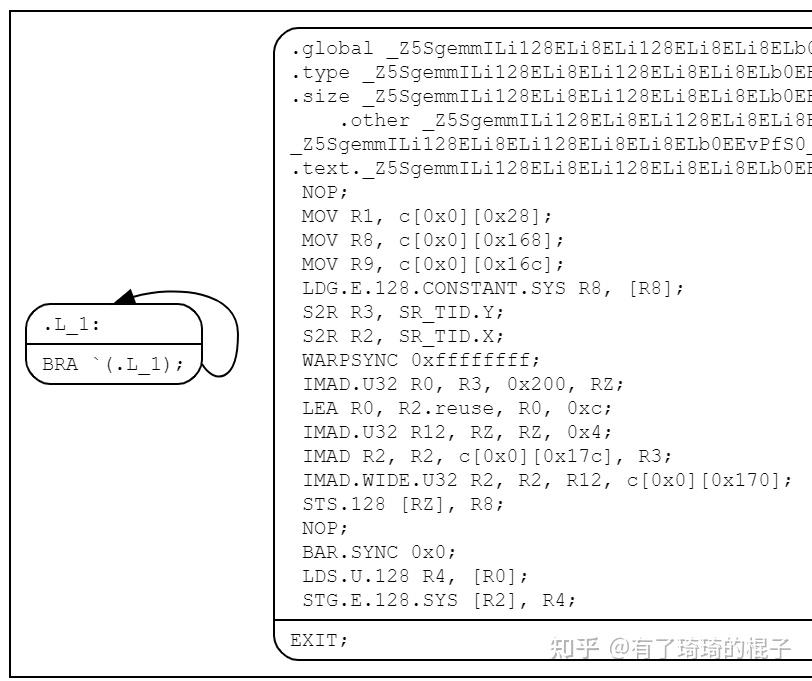
分析一下其汇编指令,可以看到,里面有4条IMAD,主要是用来做地址偏移。4条访存指令,分别是:LDG.E.128 STS.128 LDS.U.128 STG.E.128。都是128bit带宽的指令,用来移动数据。除此以外,没有判断指令和加法指令,因而#pragma unroll已经被完全展开。
结论:尽可能地在编译期间就确定for循环的展开次数等信息,一定要从外部传入的话,可以通过模板参数解决。而后采用#pragma unroll,编译器会自动地进行展开。开发者没必要手动地去展开,这个部分编译器已经做得足够好了。







